map是在编程中使用频繁的数据结构,大部分语言都会有map相似的结构。
一、结构
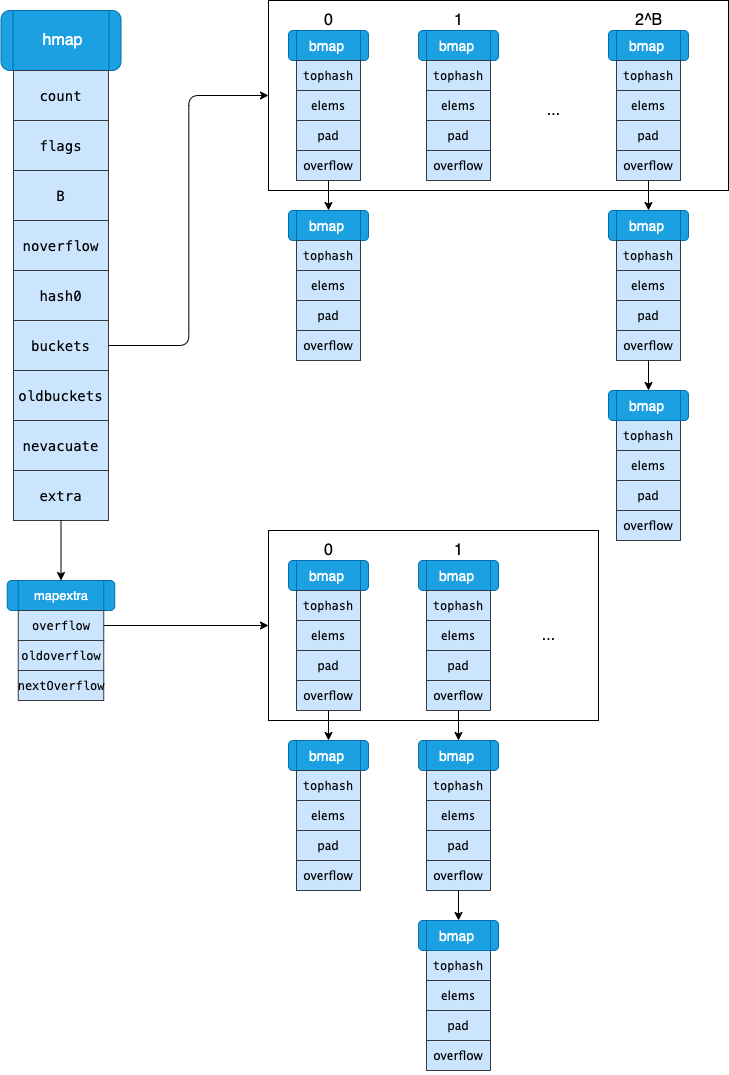
1、hmap
1 | type hmap struct { |
- count:map 的大小,也就是 len() 的值。代指 map 中的键值对个数
- flags:状态标识,主要是goroutine写入和扩容机制的相关状态控制。并发读写的判断条件之一就是该值
- B:表示当前哈希表持有的 buckets 数量,但是因为哈希表中桶的数量都2的倍数,所以该字段会存储对数,也就是len(buckets) == 2^B
- noverflow:溢出桶的数量
- hash0:是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入
- buckets:保存当前桶数据的指针地址(指向一段连续的内存地址,主要存储键值对数据)
- oldbuckets:是哈希在扩容时用于保存之前buckets的字段,它的大小是当前buckets的一半
- nevacuate:迁移进度
- extra:原有buckets满载后,会发生扩容动作,在Go的机制中使用了增量扩容,如下为细项:
overflow 为hmap.buckets(当前)溢出桶的指针地址
oldoverflow 为hmap.oldbuckets(旧)溢出桶的指针地址
nextOverflow 为空闲溢出桶的指针地址
2、bmap
哈希表hmap的桶就是bmap,每一个bmap都能存储8个键值对,当哈希表中存储的数据过多,单个桶无法装满时就会使用extra.overflow中桶存储溢出的数据。上述两种不同的桶在内存中是连续存储的,我们在这里将它们分别称为正常桶和溢出桶。
这个桶的结构体bmap在Go语言源代码中的定义只包含一个简单的tophash字段,tophash存储了键的哈希的高8位,通过比较不同键的哈希的高8位可以减少访问键值对次数以提高性能。
1 | bucketCntBits = 3 |
看到这里会懵逼,这个bmap能存放什么内容呢?map结构的设计要求存放不同类型的键值对,而golang又不支持泛型。所以键值对占据的内存空间大小只能在编译时进行推导,这些字段在运行时也都是通过计算内存地址的方式直接访问的,所以它的定义中就没有包含这些字段,但是我们能根据编译期间的 cmd/compile/internal/gc.bmap()(reflect.go) 函数对它的结构重建:
1 | func bmap(t *types.Type) *types.Type { |
因此推断出的bmap结构如下:
1 | type bmap struct { |
- tophash:key的hash值高8位
- keys:8个key
- elems:8个value
- pad:通过释放pad的填充来抢占先机,保证overflow是结构中的最后一块内存
- overflow:下一个溢出桶的指针地址(当 hash 冲突发生时)
综上,map的结构如下图:
二、初始化
从runtime.map.go中我们可以看到map的创建有三个方法:makemap64、makemap_small、makemap。我们分别来看一下。
1、makemap_small
1 | func makemap_small() *hmap { |
- 当我们使用make(map[k]v)方法创建map的时候(也就是没有指定map大小的情况),会通过makemap_small()创建。
- 使用make(map[k]v, hint) 来创建的话,如果hint小于等于bucketCnt(8个)的时候,也会通过makemap_small()创建。
- map被分配到堆上。
2、makemap
1 | func makemap(t *maptype, hint int, h *hmap) *hmap { |
1、计算哈希占用的内存是否溢出或者超出能分配的最大值;
2、调用 fastrand 获取一个随机的哈希种子;
3、根据传入的 hint 计算出需要的最小需要的桶的数量;
3、(当hint大于等于8)第一次初始化map时,就会通过调用makeBucketArray对buckets进行分配;
1 | func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) { |
makeBucketArray会根据传入的B计算出的需要创建的桶数量在内存中分配一片连续的空间用于存储数据。当桶的数量小于2^4时,由于数据较少、使用溢出桶的可能性较低,这时就会省略创建的过程以减少额外开销;当桶的数量多于2^4 时,就会额外创建2^𝐵−4个溢出桶。
3、makemap64
makemap64仅针对int64的hint做了校验,同样也是通过makemap方法创建
1 | func makemap64(t *maptype, hint int64, h *hmap) *hmap { |
三、数据访问
map的访问主要有两种方式:mapaccess1、mapaccess2。
mapaccess1的方式为接收字段为一个也就是value :=map[key]的方式。
mapaccess2的方式为接收字段为两个也就是value,ok:=map[key]的方式。
总体流程如图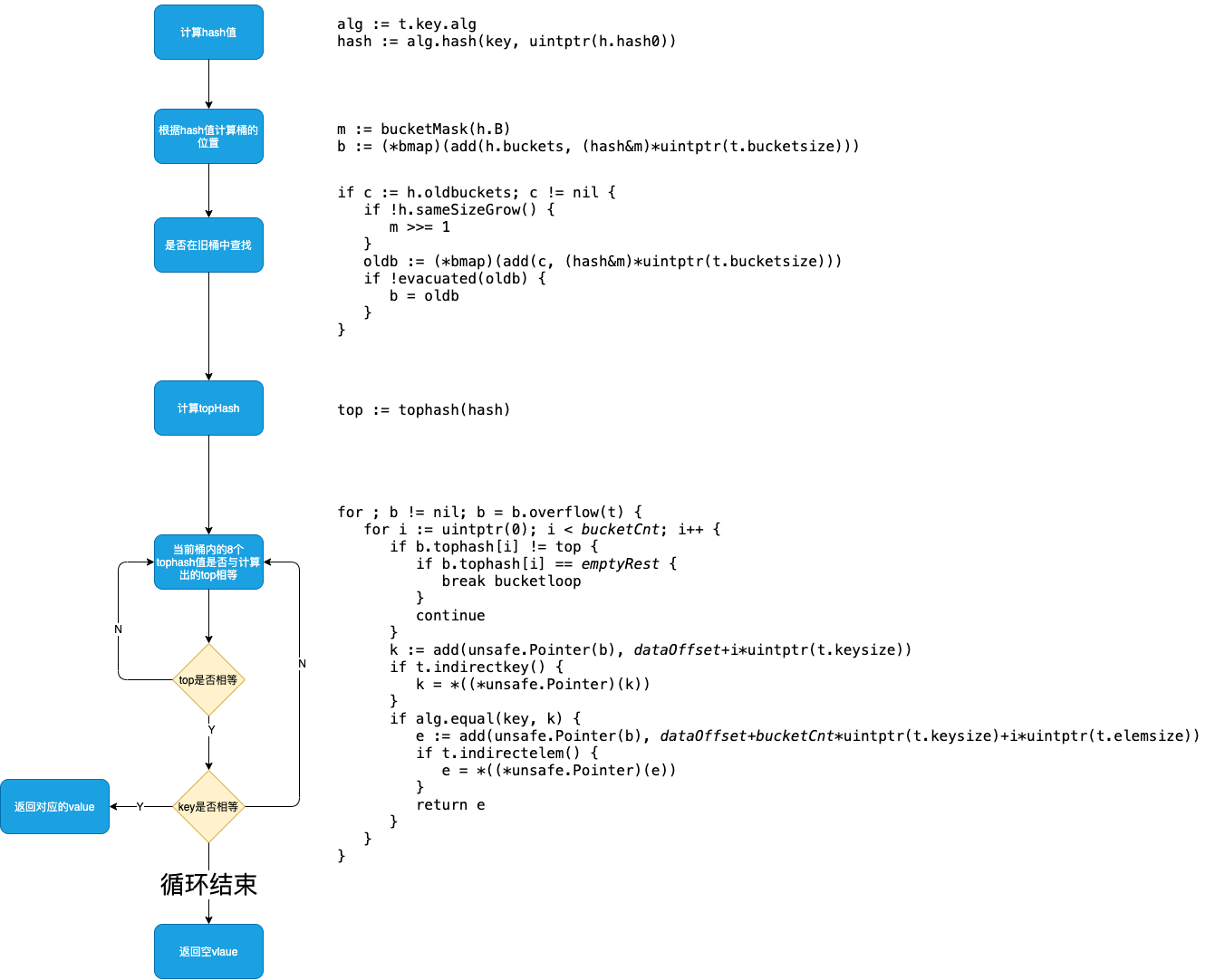
mapaccess1
1 | func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
1、判断map是否为nil,长度是否为0。若是则返回零值
2、判断当前是否并发读写map,若是则抛出异常
3、根据key的不同类型调用不同的hash方法计算得出 hash 值
4、确定key在哪一个bucket中,并得到其位置
5、判断是否正在发生扩容(h.oldbuckets 是否为 nil),若正在扩容,则到老的buckets中查找(因为buckets中可能还没有值,搬迁未完成),若该bucket已经搬迁完毕。则到buckets中继续查找
6、计算hash的tophash值(高八位)
7、根据计算出来的tophash,依次循环对比buckets的tophash值(快速试错)
8、如果tophash匹配成功,则计算key的所在位置,正式完整的对比两个key是否一致
9、若查找成功并返回,若不存在,则返回零值
mapaccess2
mapaccess2与mapaccess1类似,在返回的时候加了bool值。
四、数据写入
map的写入通过mapassign方法实现,与mapaccess1方式类似。
1 | func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer { |
形如map[key]的表达式出现在赋值符号左侧时,该表达式也会在编译期间转换成调用runtime.mapassign函数,首先是函数会根据传入的键拿到对应的哈希和桶.
然后通过遍历比较桶中存储的tophash和键的哈希,如果找到了相同结果就会获取目标位置的地址并返回,其中inserti表示目标元素的在桶中的索引,insertk和val分别表示键值对的地址,获得目标地址之后会直接通过算术计算进行寻址获得键值对k和val。
在for循环中会依次遍历正常桶和溢出桶中存储的数据,整个过程会依次判断tophash是否相等、key是否相等,遍历结束后会从循环中跳出。
四、扩容
在数据写入过程中会涉及到扩容的问题。当装载因子已经超过6.5或哈希使用了太多溢出桶的时候会触发扩容。
1 | if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) { |
判断是不是sameSizeGrow等大小”扩容”。过多的overflow使用,使用等大小的buckets重新整理,回收多余的overflow桶,提高map读写效率,减少溢出桶占用。
首先将原有的桶数组设置到oldbuckets,创建一组新桶和预创建的溢出桶,随后将新的空桶设置到buckets上,溢出桶也使用了相同的逻辑进行更新。
在hashGrow()中只是标记扩容,申请空间等初始化功能。实际的复制动作实在growWork() and evacuate()中增量的进行。
1 | func hashGrow(t *maptype, h *hmap) { |
在assign和delete操作中,都会触发扩容growWork:
确保我们接下来的使用,相应的将oldbucket转移到bucket中。再搬迁一次搬迁过程中的桶确保扩容进度。
1 | func growWork(t *maptype, h *hmap, bucket uintptr) { |
一般来说,新桶数组大小是原来的2倍(在!sameSizeGrow()条件下)。搬迁过程如下,首先了解一下变量的含义。
| 变量 | 释义 |
|---|---|
| x *bmap | 桶x表示与在旧桶时相同的位置,即位于新桶前半段 |
| y *bmap | 桶y表示与在旧桶时相同的位置+旧桶数组大小,即位于新桶后半段 |
| xi int | 桶x的slot索引 |
| yi int | 桶y的slot索引 |
| xk unsafe.Pointer | 桶y的slot索引 |
| yi int | 索引xi对应的key地址 |
| yk unsafe.Pointer | 索引yi对应的key地址 |
| xv unsafe.Pointer | 索引xi对应的value地址 |
| yv unsafe.Pointer | 索引yi对应的value地址 |
假设旧桶数组大小为2^B, 新桶数组大小为2*2^B,对于某个hash值X若 X & (2^B) == 0,说明 X < 2^B,那么它将落入与旧桶集合相同的索引xi中;否则,它将落入xi + 2^B中。
扩容过程如图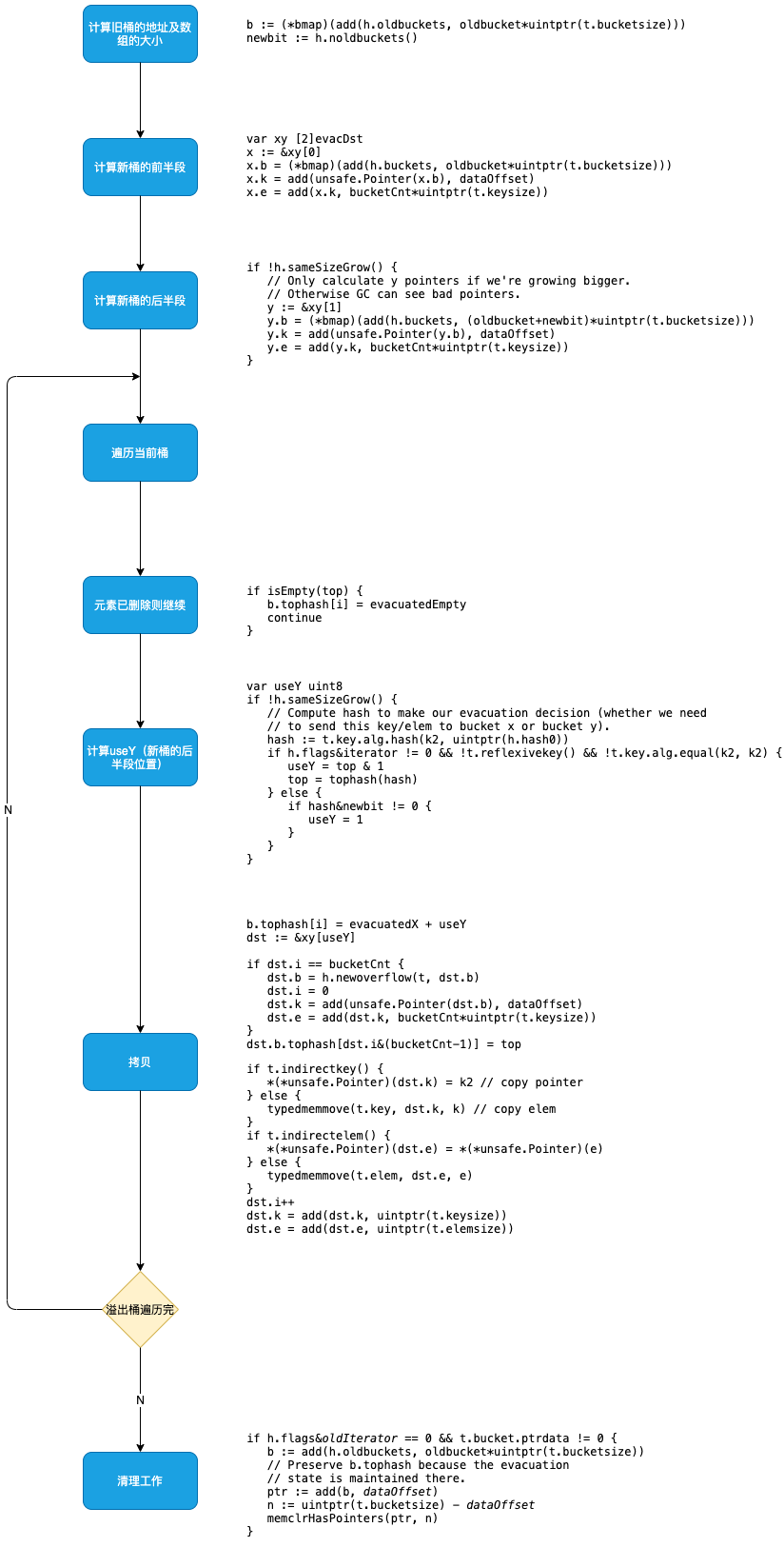
1 | func evacuate(t *maptype, h *hmap, oldbucket uintptr) { |