Go是一种垃圾回收语言。这使得编写Go更简单,因为你可以花更少的时间来担心管理分配对象的寿命。
Go中的内存管理绝对比C++中的要简单。但这也不是一个我们作为Go开发者可以完全忽视的领域。了解Go是如何分配和释放内存的,可以让我们编写更好、更高效的应用程序。垃圾收集器是这个难题的关键部分。
为了更好地了解垃圾收集器是如何工作的,我决定在一个活的应用程序上追踪它的底层行为。在这次调查中,我将用eBPF上行测试Go的垃圾收集器。这篇文章的源代码在这里。
潜在深入研究之前的几件事
在深入研究之前,让我们快速了解一下上行线、垃圾收集器的设计以及我们将要使用的演示程序的一些情况。
为什么是uprobes?
uprobes很酷,因为它可以让我们在不修改代码的情况下动态地收集新信息。当你不能或不想重新部署你的应用时,这很有用–也许是因为它在生产中,或者有趣的行为难以重现。
函数参数、返回值、延迟和时间戳都可以通过uprobes来收集。在这篇文章中,我将在Go垃圾收集器的关键函数上部署uprobes。这将使我能够看到它在我运行的应用程序中的实际表现。
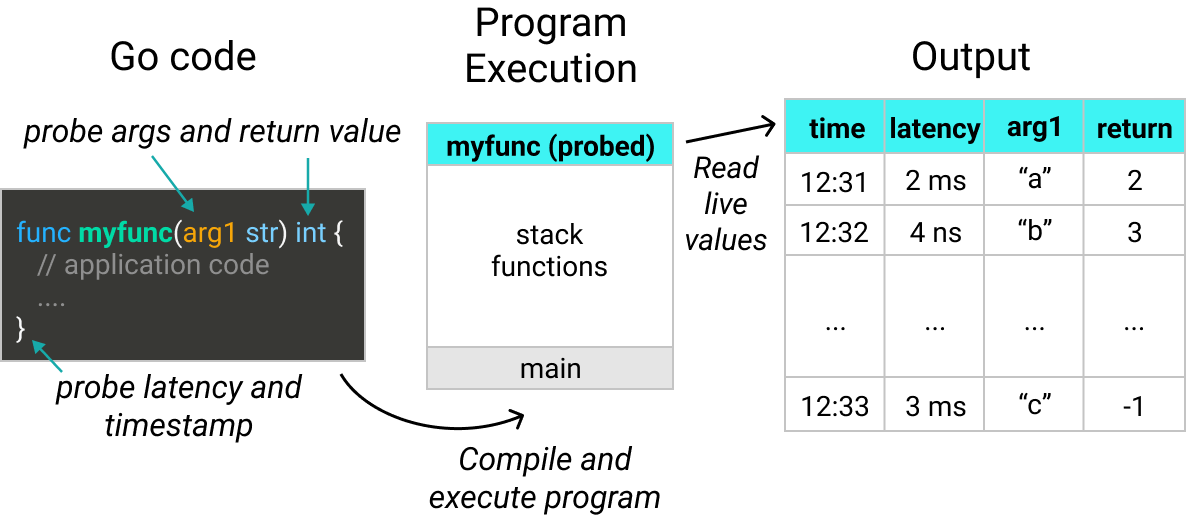
uprobes可以追踪延迟、时间戳、参数和函数的返回值
注意:本帖使用Go 1.16。我将追踪Go运行时中的私有函数。然而,这些函数在以后的Go版本中可能会有变化。
垃圾收集的阶段
Go使用了一个并发标记和扫除垃圾收集器。对于那些不熟悉这些术语的人来说,这里有一个快速的总结,以便你能理解文章的其余部分。你可以在这里、这里、这里和这里找到更详细的信息。
Go的垃圾收集器被称为并发式,因为它可以安全地与主程序并行运行。换句话说,它不需要*停止你的程序的执行来完成它的工作。(*后文将详细介绍)。
垃圾收集有两个主要阶段。
标记阶段: 识别并标记程序不再需要的对象。
清除阶段: 对于每一个被标记阶段标记为 “不可及 “的对象,释放内存以用于其他地方。
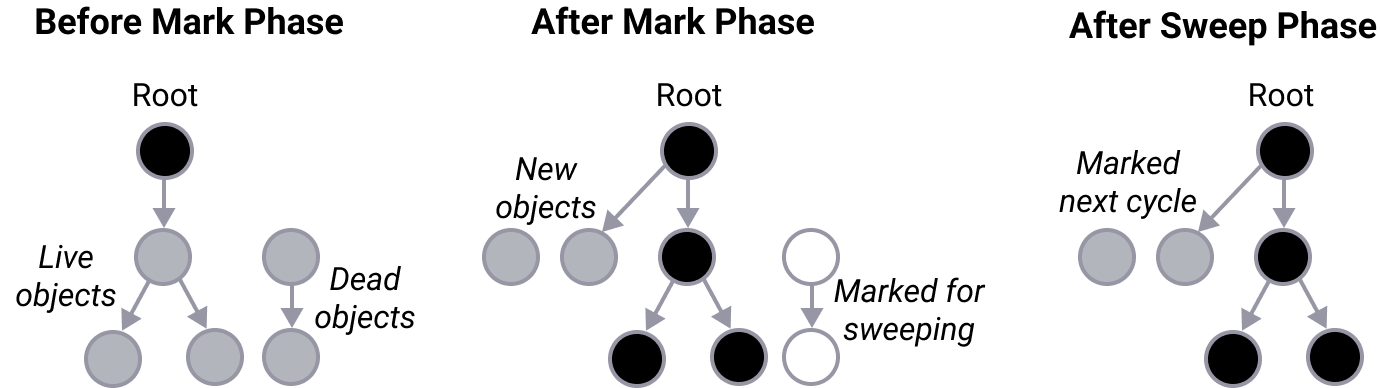
一种节点着色算法。黑色物体仍在使用中。白色物体已经准备好被清理了。灰色物体仍然需要被归类为黑色或白色。
一个简单的演示应用程序
这里有一个简单的端点,我将用它来触发垃圾收集器。它创建了一个大小不一的字符串数组。然后它通过runtime.GC()调用垃圾收集器。
通常情况下,你不需要手动调用垃圾收集器,因为Go会为你处理。然而,这保证了它在每次调用API后都会启动。
1 | http.HandleFunc("/allocate-memory-and-run-gc", func(w http.ResponseWriter, r *http.Request) { |
追踪垃圾收集的主要阶段
现在我们有了一些关于uprobes和Go的垃圾收集器的基础知识,让我们深入观察其行为。
追踪 runtime.GC()
首先,我决定在Go的runtime库中为以下函数添加上uprobes。
| Function | Description |
|---|---|
| GC | Invokes the GC |
| gcWaitOnMark | Waits for the mark phase to complete |
| gcSweep | Performs the sweep phase |
(如果你有兴趣看看上行线是如何产生的,这里有代码)。
在部署了uprobes后,我点击了端点,生成了一个包含10个字符串的数组,每个字符串都是20字节。
1 | $ curl '127.0.0.1/allocate-memory-and-run-gc?arrayLength=10&bytesPerElement=20' |
部署的uprobes在curl调用后观察到以下事件: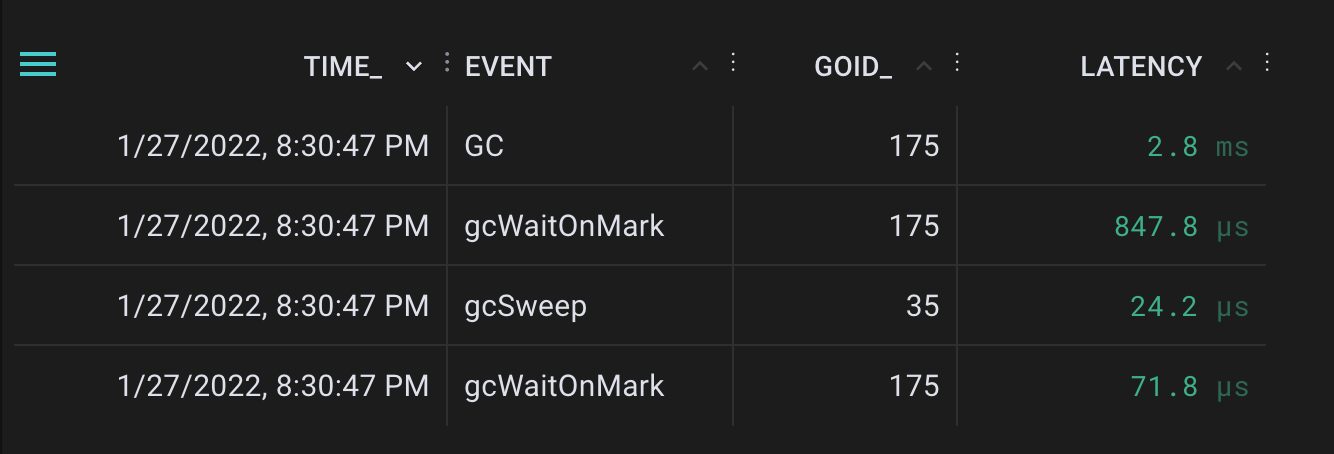
运行垃圾收集器后,为GC、gcWaitOnMark和gcSweep收集了事件
从源代码中可以看出这一点–gcWaitOnMark被调用了两次,一次是在开始下一个周期之前对前一个周期的验证。标记阶段会触发扫频阶段。
接下来,我测量了一些runtime.GC的延迟,这些延迟是在使用各种输入的/allocate-memory-and-run-gc端点后进行的。
| arrayLength | bytesPerElement | Approximate size (B) | GC latency (ms) | GC throughput (MB/s) |
|---|---|---|---|---|
| 100 | 1,000 | 100,000 | 3.2 | |
| 1,000 | 1,000 | 1,000,000 | 8.5 | 118 |
| 10,000 | 1,000 | 10,000,000 | 53.7 | 186 |
| 100 | 10,000 | 1,000,000 | 3.2 | 313 |
| 1,000 | 10,000 | 10,000,000 | 12.4 | 807 |
| 10,000 | 10,000 | 100,000,000 | 96.2 | 1,039 |
追踪标记和清除阶段
虽然这是一个很好的高层视图,但我们可以使用更多的细节。接下来,我探测了一些用于内存分配、标记和清扫的辅助函数,以获得下一层次的信息。
这些辅助函数有参数或返回值,可以帮助我们更好地可视化正在发生的事情(例如,分配的内存页面)。
| Function | Description | Info captured |
|---|---|---|
| allocSpan | Allocates new memory | Pages of memory allocated |
| gcDrainN | Performs N units of marking work | Units of marking work performed |
| sweepone | Sweeps memory from a span | Pages of memory swept |
1 | $ curl '127.0.0.1/allocate-memory-and-run-gc?arrayLength=20000&bytesPerElement=4096' |
在给垃圾收集器增加一些负载后,以下是原始结果。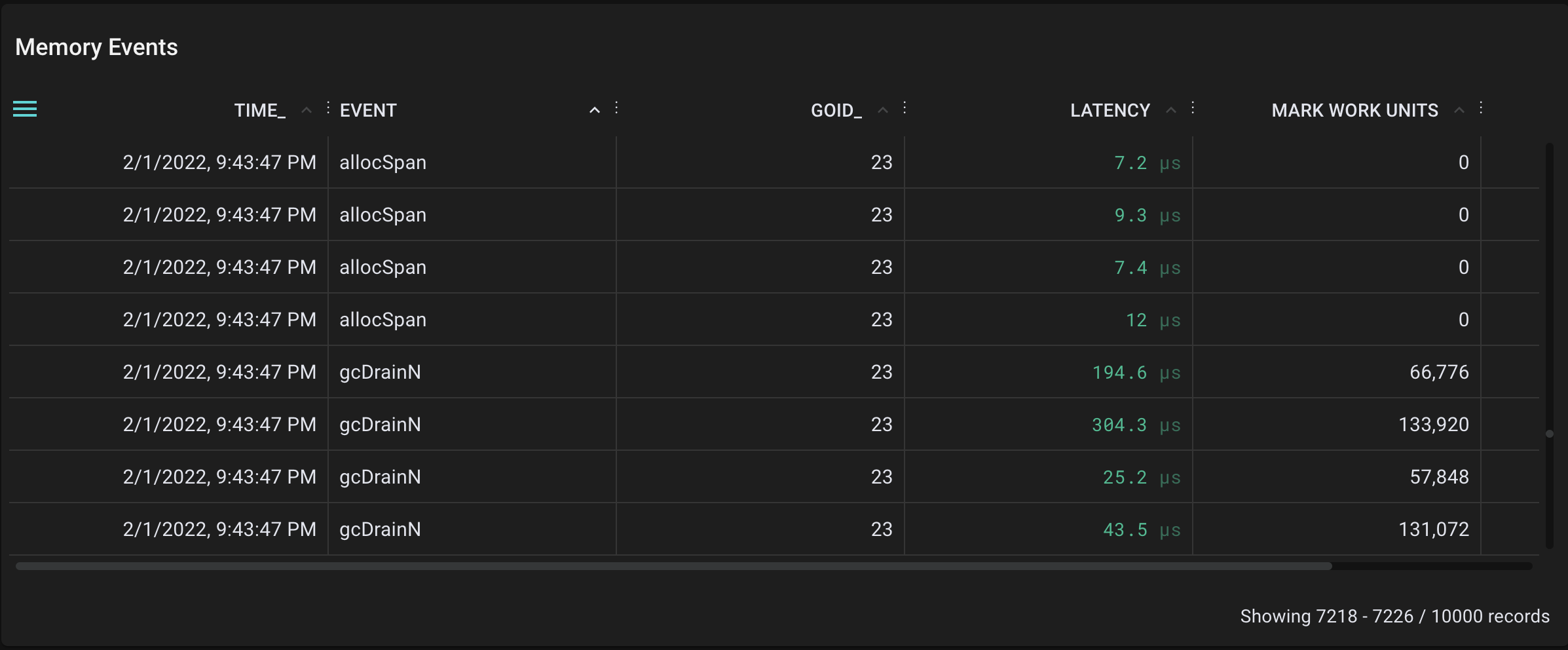
在调用垃圾收集器后,为allocSpan、gcDrainN和sweepone收集的事件样本
当绘制成时间序列时,它们更容易解释: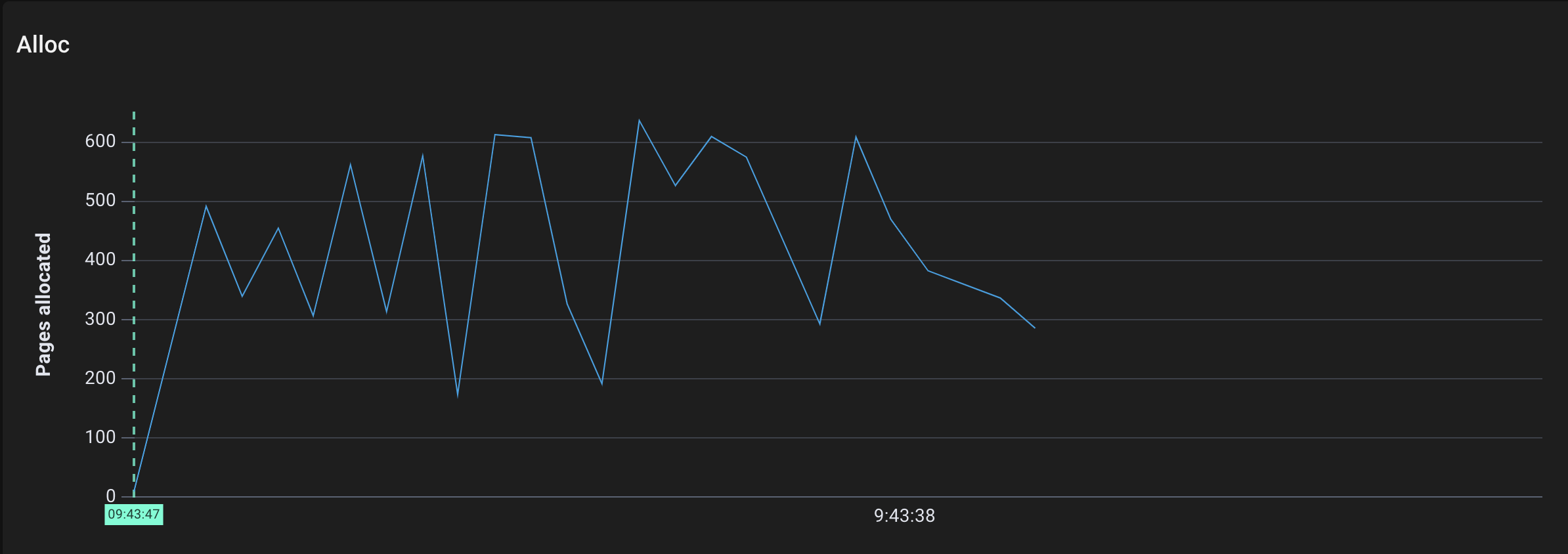
Pages allocated by allocSpan over time
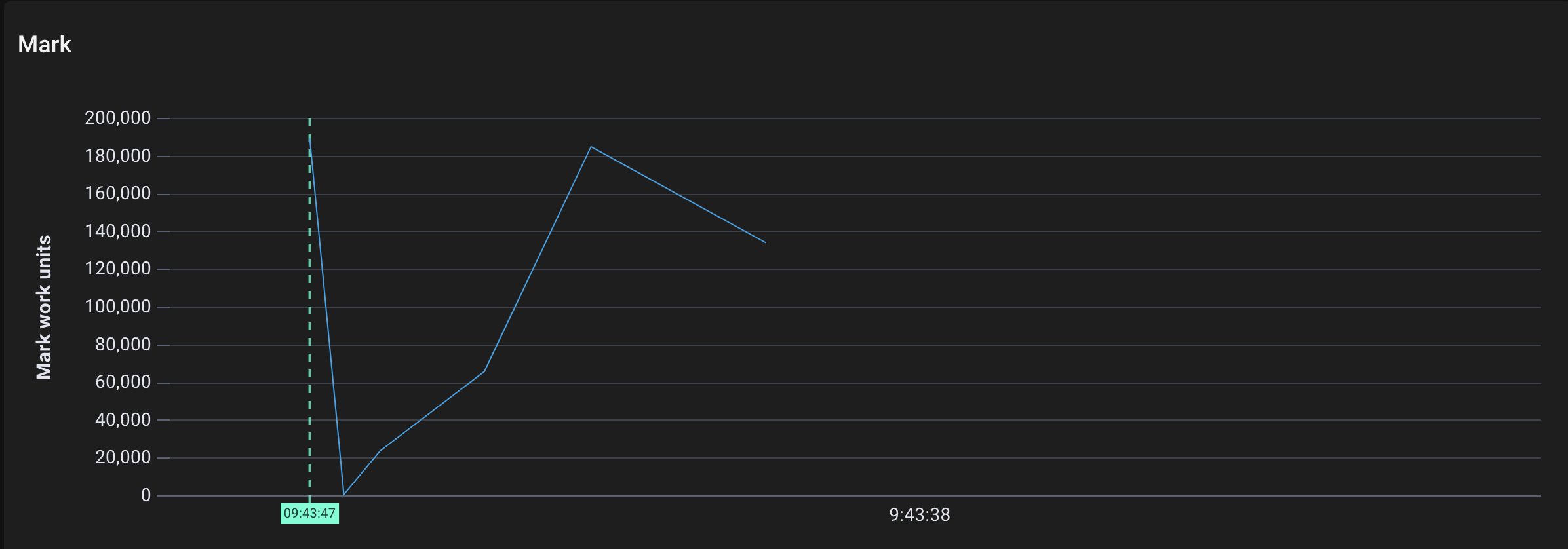
Mark work performed by gcDrain over time
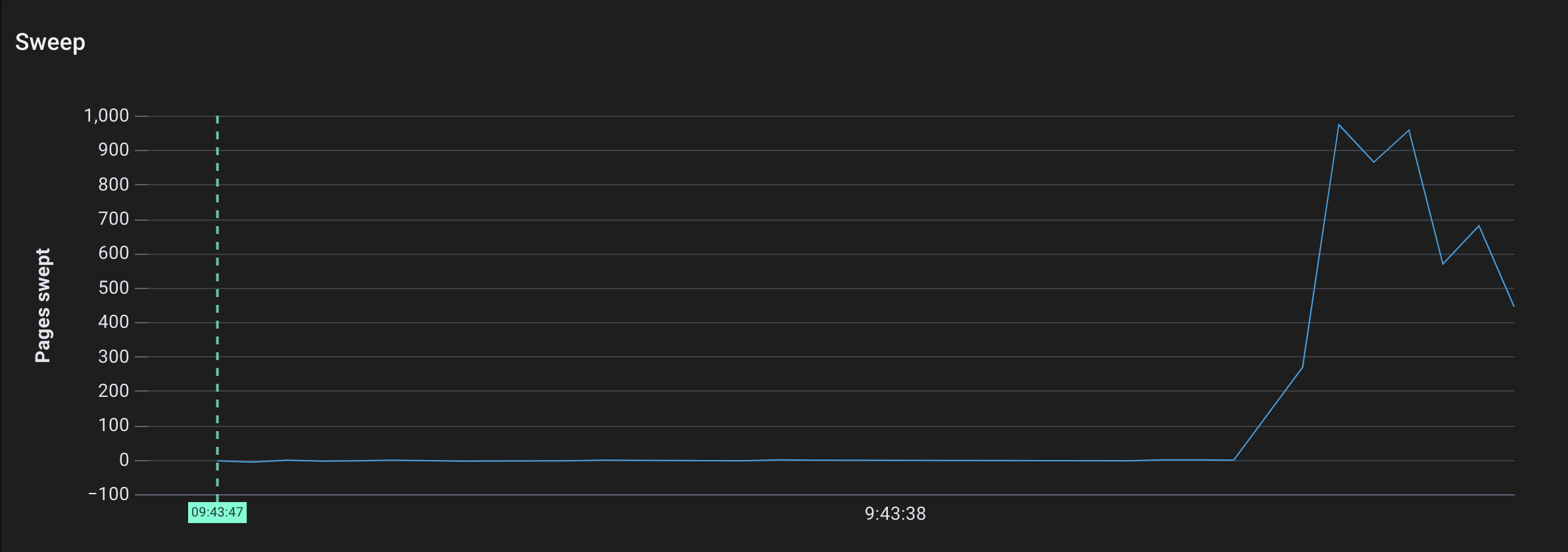
Pages swept by sweepone over time
现在我们可以看到发生了什么:
- Go分配了几千个page,这很合理,因为我们直接向堆中添加了~80MB的字符串。
- 标记工作开始了(注意,它的单位不是页,而是标记工作单位)
- 标记的页面被清扫器清扫。(这应该是所有的页面,因为我们在调用完成后并没有重复使用字符串数组)。
追踪 “Stop The World “事件
“Stop The World “是指垃圾收集器为了安全地修改状态,暂时停止了除其自身之外的一切。我们通常喜欢尽量减少STW阶段,因为它们会拖慢我们的程序(通常是在最不方便的时候……)。
有些垃圾收集器在垃圾收集运行的整个过程中停止世界。这些是 “非并发的 “垃圾收集器。虽然Go的垃圾收集器在很大程度上是并发的,但我们可以从代码中看到,它在技术上确实在两个地方停止了世界。
让我们来追踪以下函数:
| Function | Description |
|---|---|
| stopTheWorldWithSema | 停止其他程序,直到startTheWorldWithSema被调用 |
| startTheWorldWithSema | 将被停止的程序重新启动 |
并再次触发垃圾收集:
1 | $ curl '127.0.0.1/allocate-memory-and-run-gc?arrayLength=10&bytesPerElement=20' |
新探针产生了以下事件: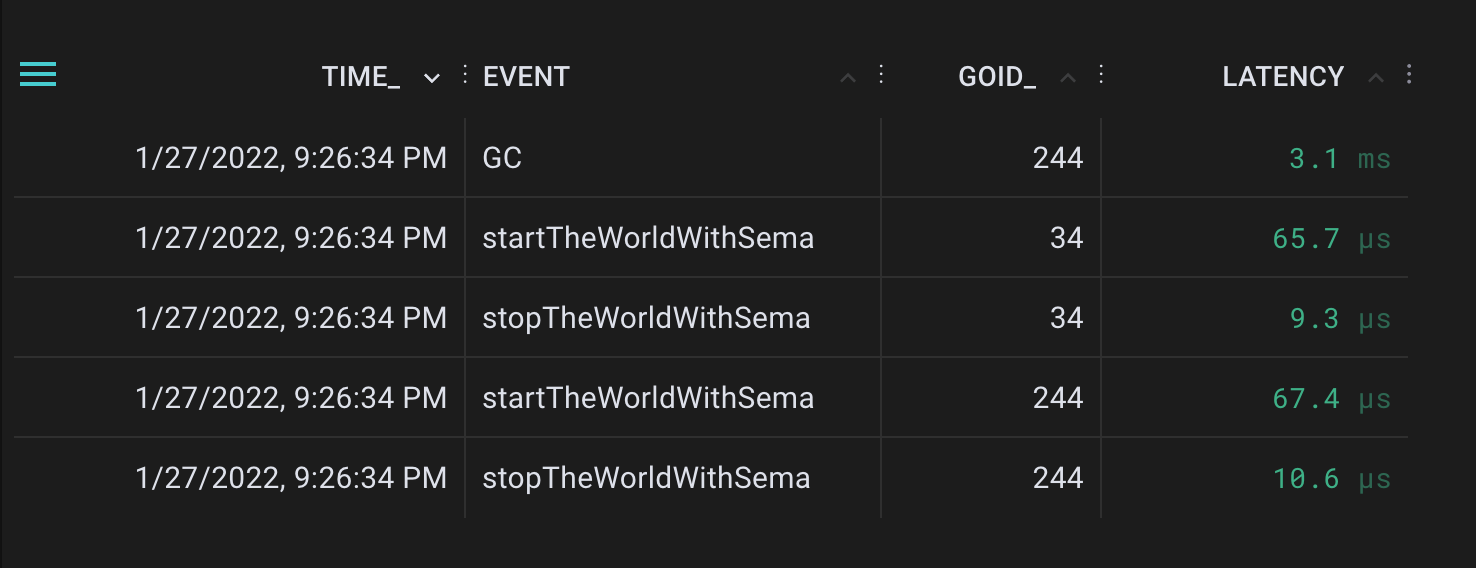
Generated start and stop the world events
我们可以从GC事件中看到,垃圾收集需要3.1毫秒才能完成。在我检查了确切的时间戳后,发现世界第一次被停止了300微秒,第二次被停止了365微秒。换句话说,~80%的垃圾收集是同时进行的。我们希望当垃圾收集器在真正的内存压力下被 “自然 “调用时,这个比例会变得更好。
为什么Go的垃圾收集器需要停止世界?
第1次STW(在标记阶段之前):设置状态并打开写屏障。写入屏障确保在GC运行时正确地跟踪新的写入(这样它们就不会被意外地释放或保留在周围)。
第2次STW(标记阶段之后): 清理标记状态,关闭写屏障。
垃圾收集器是如何进行自我调整的?
对于像Go这样的并发式垃圾收集器,知道何时运行垃圾收集是一个重要的考虑因素。
早期的垃圾收集器被设计为一旦达到一定的内存消耗水平就会启动。如果垃圾收集器是非并发的,这就很好用。但是对于一个并发的垃圾收集器,主程序在垃圾收集期间仍然在运行–因此仍然在分配内存。
这意味着如果我们太晚运行垃圾收集器的话,我们可能会超额完成内存目标。(Go也不能一直运行垃圾收集–GC会占用主程序的资源和性能)。
Go的垃圾收集器使用一个pacer来估计垃圾收集的最佳时间。这有助于Go实现其内存和CPU目标,而不至于牺牲更多的应用程序性能。
触发率
正如我们刚刚建立的,Go的并发式垃圾收集器依靠一个pacer来决定何时进行垃圾收集。但它是如何做出这个决定的呢?
每次垃圾收集器被调用时,pacer都会更新其内部目标,以确定下一次应该何时运行GC。这个目标被称为触发率。触发率为0.6意味着,一旦堆的大小增加了60%,系统就应该再次运行垃圾收集。触发率考虑了CPU、内存和其他因素来产生这个数字。
让我们看看当我们一次分配大量内存时,垃圾收集器的触发率是如何变化的。我们可以通过追踪函数gcSetTriggerRatio来获取触发率。
1 | $ curl '127.0.0.1/allocate-memory-and-run-gc?arrayLength=20000&bytesPerElement=4096' |
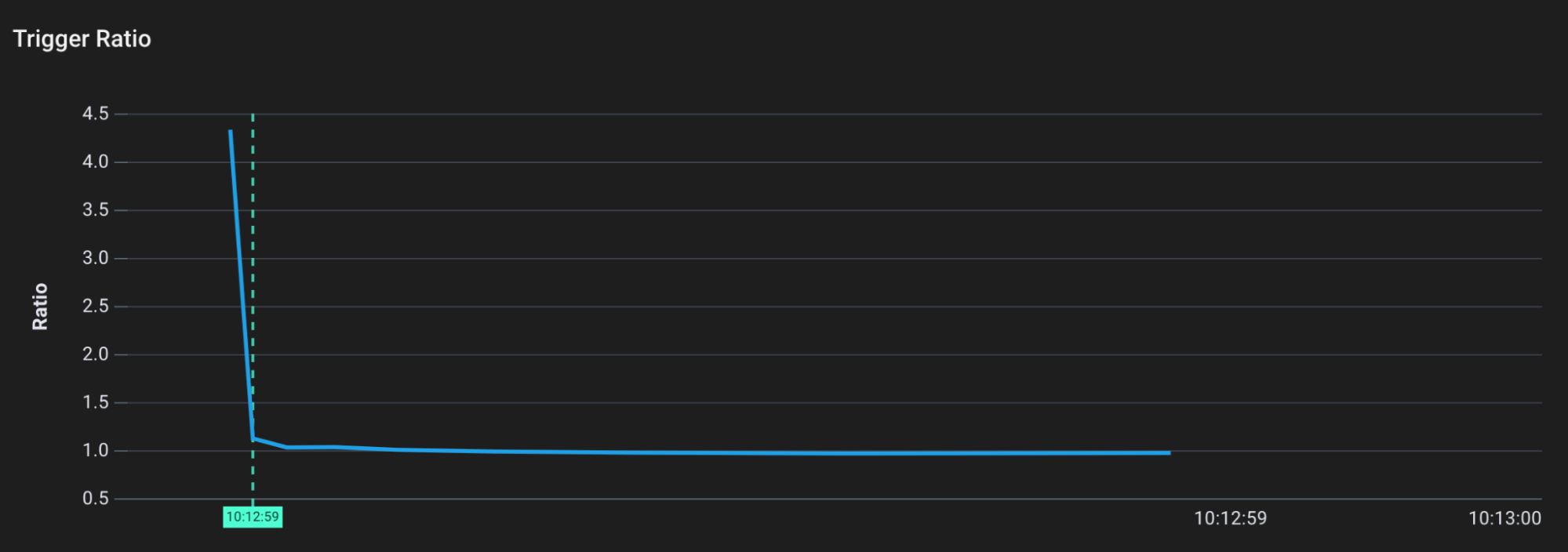
Trigger ratio over time
我们可以看到,最初,触发率是相当高的。运行时已经确定,在程序使用450%以上的内存之前,没有必要进行垃圾收集。这是有道理的,因为程序并没有做很多事情(也没有使用很多堆)。
然而,一旦我们打到终点创建81MB的堆分配,触发率迅速下降到1。现在我们只需要再多100%的内存就应该发生垃圾收集(因为我们的内存消耗上升)。
标记和辅助清扫
当我分配了内存,但不调用垃圾收集器时会发生什么?下一步我将点击/allocate-memory端点,它与/allocate-memory-and-gc做同样的事情,但跳过对runtime.GC()的调用。
1 | $ curl '127.0.0.1/allocate-memory?arrayLength=10000&bytesPerElement=10000' |
根据最近的触发率,垃圾收集器应该还没有开始工作。然而,我们看到标记和清扫仍然发生。
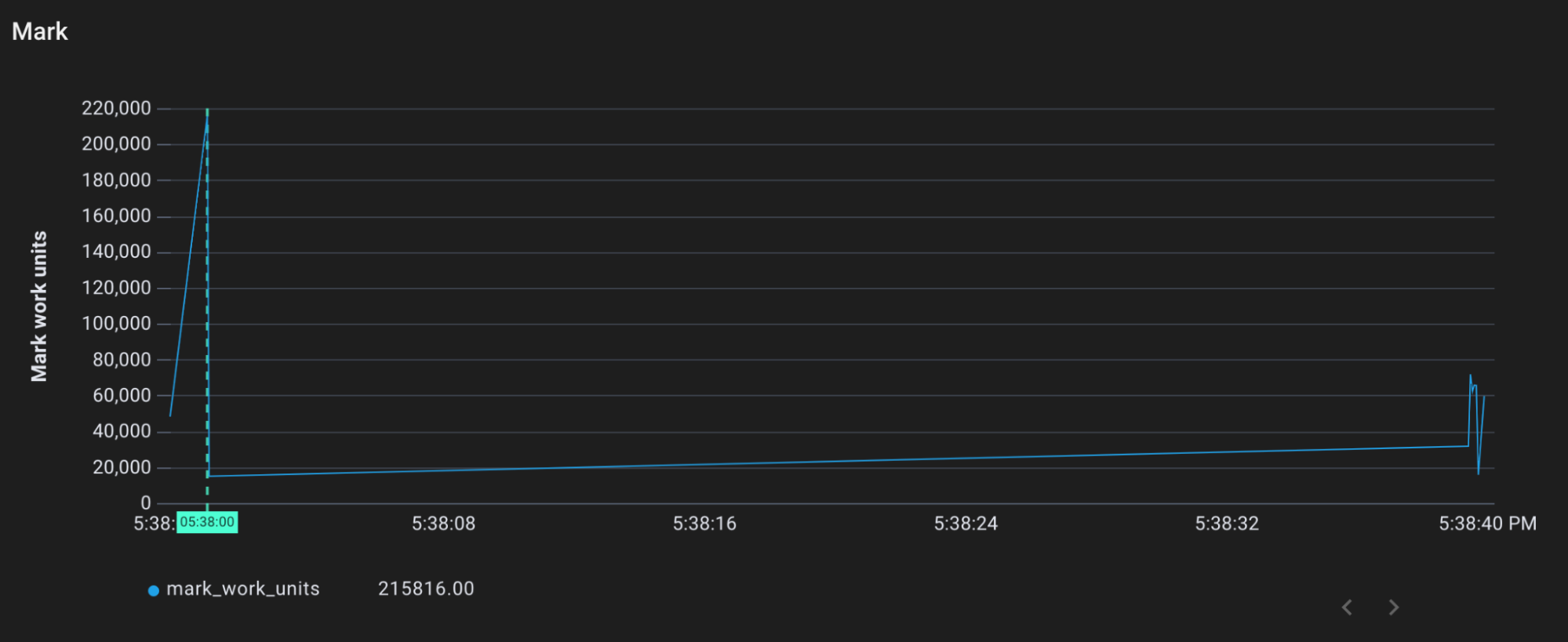
Mark work performed by gcDrain over time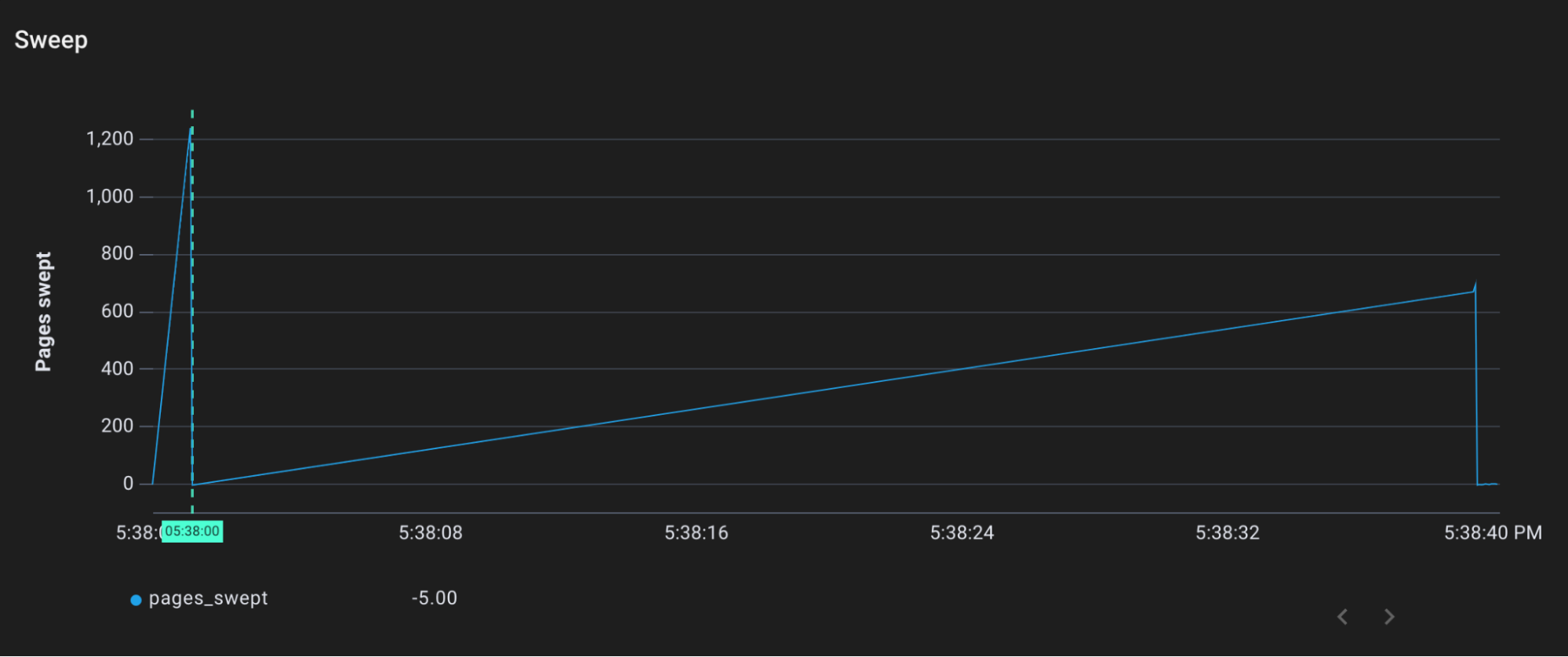
Pages swept by sweepone over time
事实证明,垃圾收集器还有一招来防止内存的失控增长。**如果堆内存开始增长过快,垃圾收集器将向分配新内存的任何人收取 “tax”**。请求新的堆分配的Goroutine将首先要协助垃圾收集器,然后才能得到他们所要求的东西。
这个 “协助 “系统增加了分配的延迟,因此有助于给系统施加反压力。这真的很重要,因为它解决了并发垃圾收集器可能产生的一个问题。在一个并发的垃圾收集器中,当垃圾收集运行时,内存分配仍在分配。如果程序分配内存的速度比垃圾收集器释放内存的速度快,那么内存的增长将是无限制的。辅助工具通过减慢(反压)新内存的净分配来解决这个问题。
我们可以跟踪gcAssistAlloc1来看看这个过程的运作。 gcAssistAlloc1接收了一个叫做scanWork的参数,这是要求的辅助工作的数量。
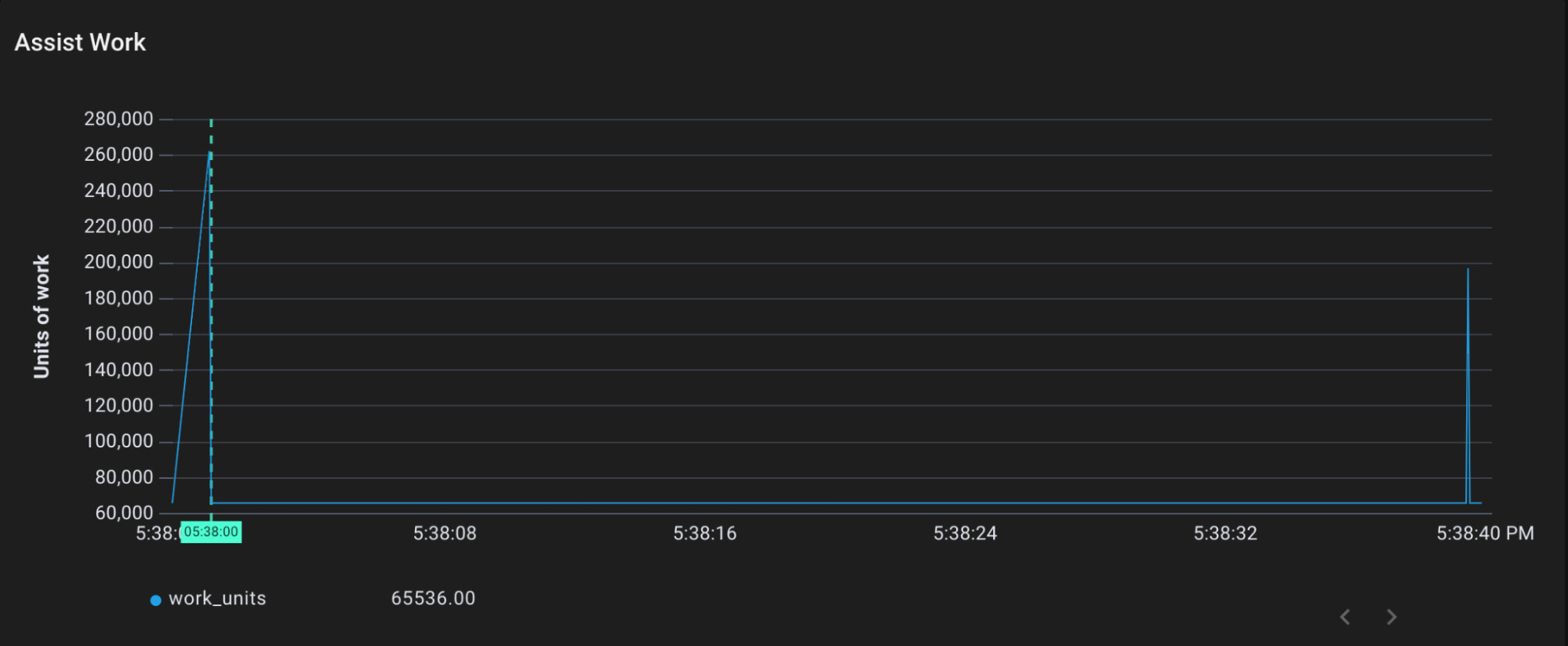
Assist work performed by gcAllocAssist1 over time
我们可以看到,gcAssistAlloc1是标记和扫除工作的来源。它收到一个请求,要完成大约300,000个单位的工作。在前面的标记阶段图中,我们可以看到gcDrainN在同一时间执行了大约30万单位的标记工作(只是分散了一些)。
总结
关于Go中的内存分配和垃圾回收,还有很多需要学习的地方。这里有一些其他的资源可以查看:
创建上行线,就像我们在这个例子中做的那样,通常最好在更高层次的BPF框架中完成。在这篇文章中,我使用了Pixie的 Dynamic Go logging 功能(目前仍在alpha阶段)。bpftrace是另一个创建上行线的好工具。你可以在这里尝试这个帖子中的整个例子。
另一个检查Go垃圾收集器行为的好办法是gc tracer。只要在启动程序时传入GODEBUG=gctrace=1即可。它需要重新启动,但会告诉你关于垃圾收集器正在做什么的各种很酷的信息。
有问题吗?请在Slack或Twitter上找到Pixie贡献者:@pixie_run。